flowy
shippedmental health journaling app. built the entire backend: ai chat, voice journaling, emotion analysis. live on the app store.
screens
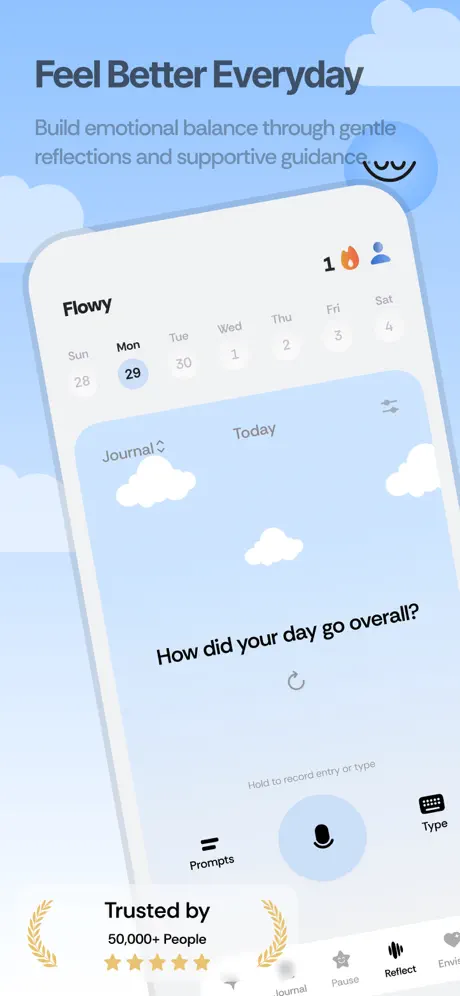
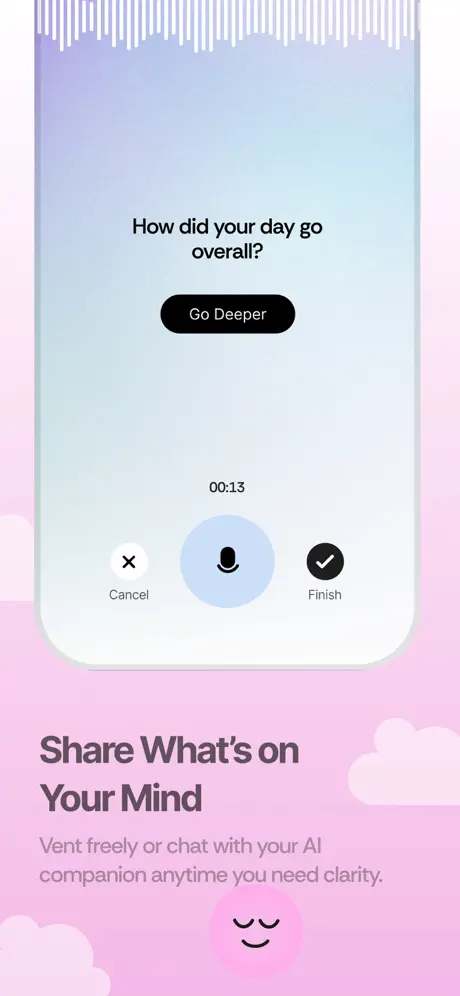
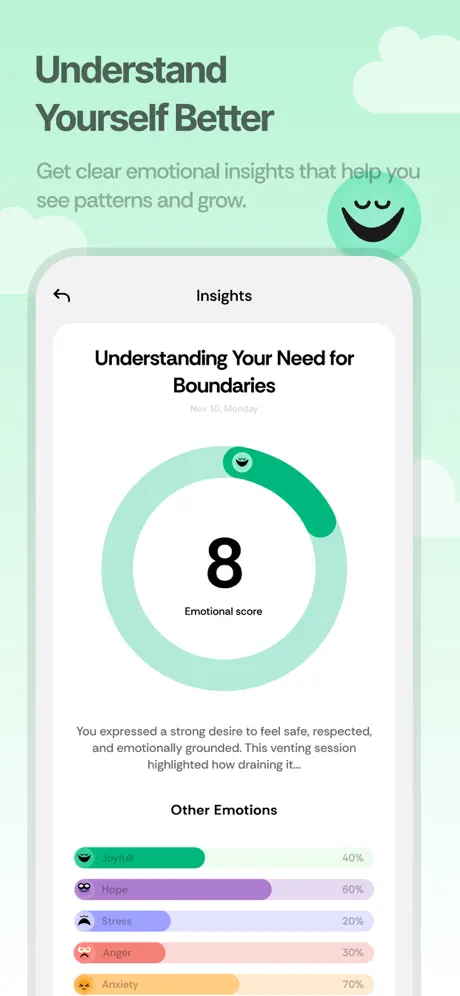
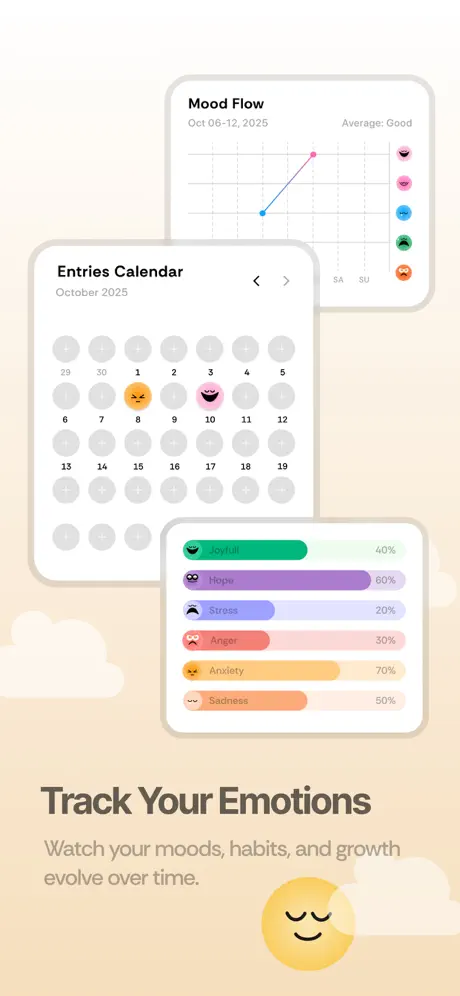
flowy is an emotional companion app. users journal by typing or talking, get thoughtful ai responses, and track how they feel over time. i built the entire backend as a freelance project: real-time ai streaming, voice transcription, emotion scoring, and daily insights generation.
how it works
- 1user creates a text or audio session. each type gets a different ai personality (detailed for text, quick one-liners for voice notes)
- 2text messages stream back via server-sent events. the ai responds in real-time, token by token
- 3audio messages get uploaded to supabase storage, transcribed by assemblyai, then the ai responds to the transcript
- 4after a conversation, gpt-4o analyzes the full session: extracts emotion score (1-4), feelings with emojis, and a short insight
- 5daily and weekly insights aggregate across sessions to surface patterns like 'journaling more on hard days' or 'mood has been trending up'
key decisions
single-table design with jsonb for chat history
one chat_sessions table stores everything: messages as jsonb, metadata as columns, full-text search via tsvector. no joins for the hot path. simple, fast, and the schema grows with the product.
dual system prompts for text vs audio
text journaling needs depth: empathetic, exploratory responses. voice notes need brevity: quick acknowledgments, not essays. same ai service, different personalities based on session type.
sse streaming over websocket
server-sent events are simpler than websockets for one-way data flow. the client sends a message via POST, the response streams back token by token. no connection management, works through every proxy.
assemblyai with polling over real-time transcription
voice notes are pre-recorded, not live. polling a transcription job (10-30 seconds) is simpler and cheaper than maintaining a real-time websocket stream for audio that's already complete.
what i built
- nestjs api with supabase auth (jwt verification), auto-creating user profiles on first request
- real-time ai chat streaming via sse with vercel ai sdk, model-agnostic, currently using gpt-4o
- audio pipeline: upload to supabase storage → transcribe with assemblyai → ai response → save to session
- ai-powered session analysis: emotion scoring, insight generation, feelings extraction with structured output (zod schema validation)
- daily and weekly insight generation aggregating patterns across sessions
- full-text search with tsvector + trigram indexing across titles and transcripts
- subscription management with webhook event handling
- sentry integration for error tracking, background job for audio cleanup
- dual stt provider support (assemblyai + deepgram)
timeline
text + audio chat flow, initial api setup
audio processing with ffmpeg, health check endpoints
user management with supabase auth integration
enhanced chat sessions with user transcripts and prompt support
daily insights generation engine
audio cleanup jobs, re-encoding, error logging improvements
sentry integration, comprehensive error logging system
refactored insights for daily + weekly, schema improvements
subscription management with webhook handling
dual stt provider support: assemblyai + deepgram